Common Introduction to all sections
This is part 5 of 10 blog posts I’m writing to convey the information that I present in various workshops and lectures that I deliver about complexity. I’m an evaluator so I think in terms of evaluation, but I’m convinced that what I’m saying is equally applicable for planning.
I wrote each post to stand on its own, but I designed the collection to provide a wide-ranging view of how research and theory in the domain of “complexity” can contribute to the ability of evaluators to show stakeholders what their programs are producing, and why. I’m going to try to produce a YouTube video on each section. When (if?) I do, I’ll edit the post to include the YT URL.
| Part | Title | Approximate post date |
| 1 | Complex systems or complex behavior? | up |
| 2 | Complexity has awkward implications for program designers and evaluators | up |
| 3 | Ignoring complexity can make sense | up |
| 4 | Complex behavior can be evaluated using comfortable, familiar methodologies | up |
| 5 | A pitch for sparse models | up |
| 6 | Joint optimization of unrelated outcomes | 7/8 |
| 7 | Why should evaluators care about emergence? | 7/16 |
| 8 | Why might it be useful to think of programs and their outcomes in terms of attractors? | 7/19 |
| 9 | A few very successful programs, or many, connected, somewhat successful programs? | 7/24 |
| 10 | Evaluating for complexity when programs are not designed that way | 7/31 |
Models
I’ll start with my take on the subject of “models”. I do not think of models exclusively in terms of traditional evaluation logic models, or in terms of the box and arrow graphics that we use to depict program theory. Rather, I think in terms of how “models” function in the process of scientific inquiry. Table 1 summarizes how I engage models when I do evaluation. [Some writings that influenced my thinking about this topic: 1) Evaluation as technology, not science (Morell), 2) Models in Science Frigg, Roman and Hartmann, 3) The Model Thinker: What You Need to Know to Make Data Work for You (Page) 4) Timelines as evaluation logic models (Morell).]
Table 1: How Jonny Thinks About Models
| Simplification | A model is a simplification of reality that deliberately omits some aspects of a phenomenon’s functioning in order to highlight others. Simplification is required because without it, no methodology could cover all relevant factors. |
| Ubiquity | Because evaluation is an analytical exercise there is always a need for some kind of a model. That model may be implicit or explicit, detailed or sparse, comprised of qualitative or quantitative concepts, and designed to drive any number of qualitative or quantitative ways of understanding a program. Also, models can vary in their half-lives. Some will remain relatively constant over an entire evaluation. Some may change with each new piece of data or each new analysis. But there will always be more going on than can be managed in any analysis. There will always be a need to decide what to strip out in order to discern relationships among elements of what is left. |
| Ignorance | No matter how smart we are, we will never know what all the relevant factors are. We cannot have a complete model no matter how hard we try. |
| Choice | Models can be cast in different forms and at different levels of detail. The appropriate form is the one that works best for a particular inquiry. |
| Multiple forms | There is no reason to restrict an inquiry to only one model, or one form of model. In fact, there are many good reasons to use multiple models. |
| Wrong but useful | George Box was right. “All models are wrong, but some are useful”. (Go here for a dated but public version. To here for the journal version.) |
| Outcome focus | I use models to guide decisions about what methodology I should employ, what data I should collect, and how I should interpret the data. I tend not to use models to explain a program. If I did, I would include more detail than I could handle in an evaluation exercise. I do not use models for program advocacy, but if I did, it would use less detail. |
A common view of models in evaluation
Considering the above, what should evaluation models look like? This question is unanswerable, but I do have a strong opinion as to what a model should not look like. It should not look almost all the models I have ever seen. It should not look like Figure 1. I know that no model used by evaluators looks exactly like this, but almost all models I have ever seen have a core logic that is similar. Qualitatively, they are all the same. I do not like these models.

One reason I do not like these models is because they do not recognize complex behavior. Here are some examples of some complex behaviors that these kinds of models miss.
- Even a single feedback loop can result in non-linear behavior
- Small perturbations in any part of the model’s behavior may result in a major change in a model’s trajectory.
- The model as a whole, or regions of it, may combine to generate effects that are not attributable to any single element in the model.
- Models as depicted in Figure 1 are cast as networks, but the model is not treated as a network that can exhibit network behavior.
- The model asserts that intermediate outcomes can be identified, as can paths through those outcomes. It is entirely possible that precise path cannot be predicted, but that long-term outcome can.
Another reason I do not like these models is because they are not modest. Read on.
Recognizing ignorance
Give all the specific detail in Figure 1 a good look. Give it the sniff test. Is it plausible that we know enough about how the program works to specify it at that

level of detail? I suppose it’s possible, but I bet not.
As an aside, I also think that if models like this are used, they should include information that they always lack. Here are two examples. 1) Are all those multiple arrows equally important? 2) Do those multiple connections represent “and”, or “or” relationships? It makes a difference because too many “and” requirements almost certainly portend that the program will fail. These are my favorites from a long list I developed for an analysis of implicit assumptions. If you want them all go to: Revealing Implicit Assumptions: Why, Where, and How?
My preference is to use models along the lines of those in Figure 2. From top to bottom, they capture a greater sense of what we do not know because we have not done enough research, or what we cannot know because of the workings of complex behaviors.
Blue model: The story in this model is that there are outcomes that matter, but whose precise relationships cannot be identified. (See the ovals in the “later”) column. The best we can do is think of these outcomes in groups such that if something happens in one group, something will happen in the subsequent group. This is the best we can do. We cannot specify relationships among single outcomes within each group, or specific outcomes across groups. Also, it is possible that for each replication of the program, the 1:1 relationship within and across groups may differ. Or, there may be no 1:1 relationships at all. Rather, there is emergent behavior in one group that is affecting the other. Or put more simply, the best we can say is that “if stuff happens here, stuff will happen there”.
Green model: The story in the middle acknowledges an even greater degree of ignorance. The intermediate outcomes are still there, but the model acknowledges that much else not related to the program might be affecting the long-range outcome. Still, that long-range outcome can be isolated and identified. This seems like an odd possibility, but I believe that it is quite possible. (See Part 8: How can the concept of “attractors” be useful in evaluation?)
Yellow model: The story at the bottom acknowledges more ignorance still. There, not only are the intermediate outcomes tangled with other activity, but the long-range outcome is as well.
I have no a priori preference for any of these models. The choice would depend on how much we know about the program, what the outcomes were, how much uncertainty we could tolerate, what data were available, what methodologies were available, the actual numbers for “later” and “much later”, and the needs of the stakeholders. What matters though, is that thinking of models in this way acknowledges the effects of complex behavior on program outcomes, and that it recognizes how little we know about the details of why a program will do what it does. Also, l I do not claim that these models are the only ones possible. They are as they say, for illustrative purposes only. Evaluators can and should be creative in fashioning models that serve the needs of their customers.
Locally right but not globally right
Models can have the odd characteristic of being everywhere locally correct but not globally correct. I tried to illustrate this with the green rectangle in Figure 3. Imagine moving that rectangle over the model. The relationships shown within the rectangle may well behave as the model depicts them, but as the size of the rectangle grows to overlap with the ent
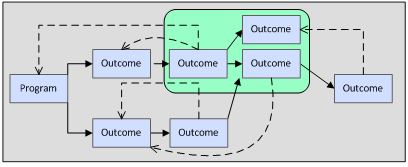
ire model, the fit between model and reality may fade. Several aspects of complex behavior explain why this is so.
- Multiple interacting elements may exhibit global behavior that cannot be explained in terms of the sum of its parts. This is the phenomenon of emergence. (Part 7 Why should evaluators care about emergence?)
- The model is a network, and networks can adapt and change as communication runs along its edges.
- Because of sensitive dependence, small changes in any part of a system can result in long term change as the system evolves. The direction of that evolution cannot be predicted. To know it, the system must run, and its behavior observed.
- All those feedback loops can result in non-linear change.
- Collections of entities and relationships like this can result in phase shift behavior, a phenomenon where the characteristics of a system can change almost instantaneously.
Summary of common themes
There are two common themes that run through everything I have said in this post.
- The models limit detail, either by removing specific element-to-element relationships, or by limiting the number and range of elements under investigation.
- They portray scenarios in which complex behavior is affecting program outcome.
These two themes are related. One of the reasons we should use sparse models is because complex behavior makes it inappropriate to specify too much detail.

Nice work Jonny. Donkey’s years ago I went to a modelling session in New Zealand run by guys who were profesional modellers. University of Utrecht and I think Sussex in the UK. They were very clear that for any form of prediction you needed complicated models, and for insights you needed (relatively) simple models. As you know I’ve written this on Evaltalk many times and still evaluators don’t get the message. Incidentally the ‘green’ version is pretty much what we use in NZ and Australia when we talk of ‘logic models’; the name we give them is ‘outcome hierarchies’. Sue Funnell developed the idea in the 1990s although of course based on results chains from operations research.