I’m in the process of working up a presentation for the upcoming conference of the American Evaluation Association:. Successful Scale-up Of Promising Pilots: Challenges, Strategies, and Measurement Considerations. (It will be a great panel. You should attend if you can.) This is the abstract for my presentation.
Title: Complex System Behavior as a Lens to Understand Program Change Across Scale, Place, and Time
Abstract: Development programs are bedeviled by the challenge of transferability. Whether from a small scale test to widespread use, or across geography, or over time, programs do not work out as planned. They may have different consequences than we expected. They may have larger or smaller impacts than we hoped for. They may morph into programs we only dimly recognize. They may not be implemented at all. The changes often seem random, and indeed, in some sense they are. But coexisting with the randomness, a complex system perspective shows us the sense, the reason, the rationality in the unexpected changes. By thinking in terms of complex system behavior we can attain a different understanding of what it means to explain, or perhaps, sometimes to predict, the mysteries of transferability. That understanding will help us choose methodologies and interpret data. It will also give us new insight on program theory.
There will only be one slide in this presentation.
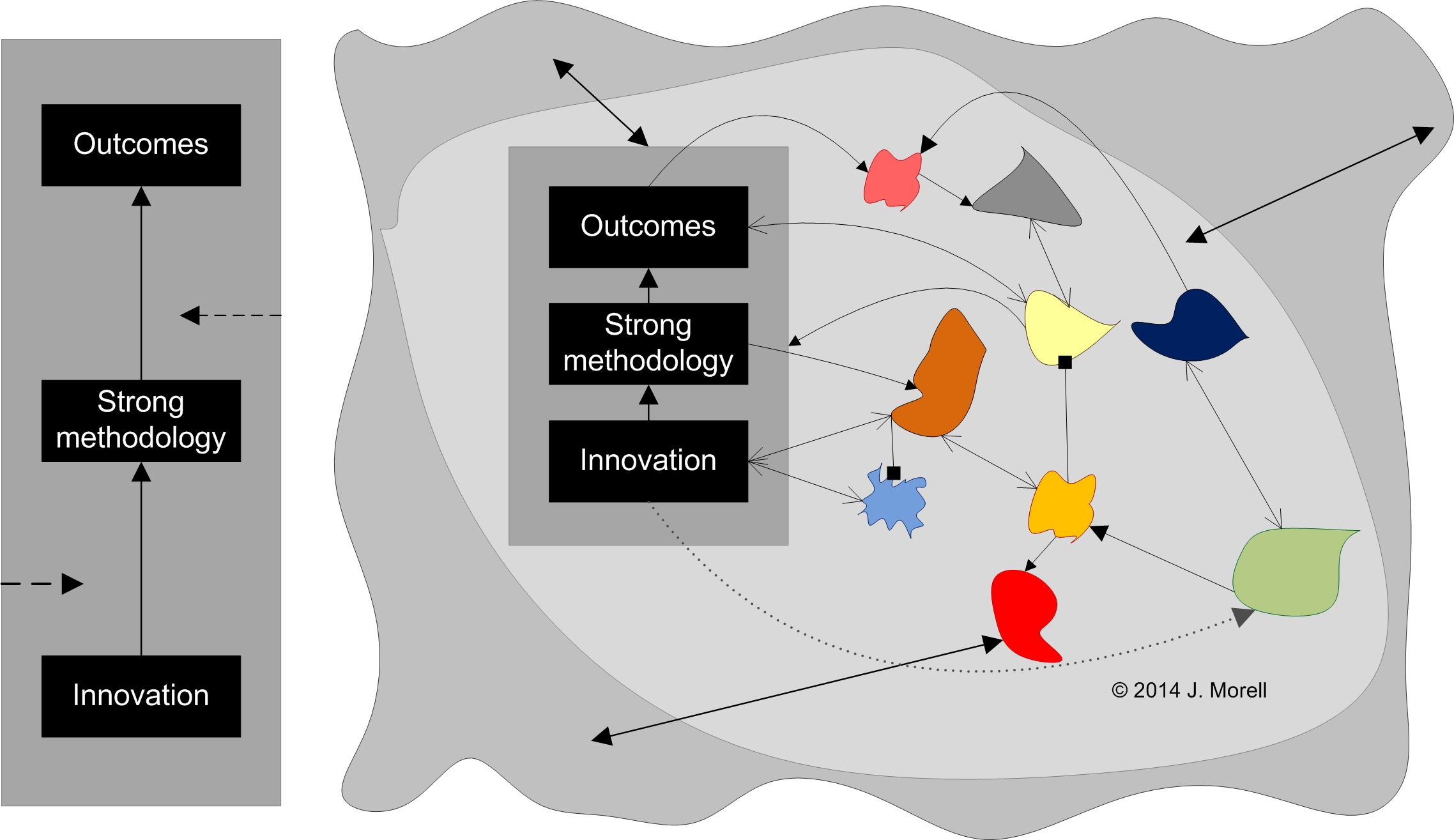
Based on this slide I’m developing talking points. I know I’ll have to abbreviate it at the presentation, but I do want a coherent story to work from. A rough draft is below. Comments appreciated. Whack away.
- The other presentations will present (or presented, depending on the order) real-world experiences in scaling-up projects that have been demonstrated to be successful. This presentation will provide a theoretical framework that will show how those experiences make sense in terms of the behavior of complex systems. Our panel members hope that between the practical example and the theoretical explanation, others will be more effective in spreading effective programs beyond their test settings.
- The picture on the left is an oversimplification of how evaluation is commonly done, but not that much of an oversimplification.
- Define the innovation.
- Use the best methodology you can.
- Measure outcomes.
- Give some attention to contextual factors.
- From the point of view of doing effective replication, what matters is that what we are really testing is not the picture on the left, but the picture on the right.
- It’s not that the methodology is weak or we can’t trust the results. We can. If the results are promising, we must. But to invoke a term not used enough anymore, we have good internal validity and weak external validity.
- Why is there an external validity problem? It is there because of the behavior of complex systems. Strange things can happen in those systems. Here are but a few.
- Small changes can cascade in unpredictable ways through the system.
- Small changes can bring about big changes.
- Big changes can have small consequences.
- All the other elements of the system can’t always be identified. It’s not that we are not smart enough, it’s because it is impossible.
- Feedback loops can produce chaotic behavior
- And much else besides.
- So where does this leave us? We cannot ignore the results of the evaluation because, after all, we have very good evidence that the program we tested can indeed produce particular outcomes. Facts are facts.
- On the other hand, all the complex system behaviors I described seem to make the situation hopeless. If all that stuff is going on, how can we ever predict what will happen?
- The answer is that sometimes complex systems can be very stable and very predictable, (although sometimes not in the sense that we commonly use those terms – Complexity is about stability and predictability). We need a sense of when complex systems are or are not stable, and then we need to start thinking about the reason for doing evaluation in a slightly different way than what we are used to.
- We need to start thinking about evaluation as providing explanation rather than prediction. In this respect two aspects of explanation are salient.
- An explanation is “a set of statements constructed to describe a set of facts which clarifies the causes, context, and consequences of those facts.”
- The value of an explanation is context dependent. Do we explain a power outage in terms of a storm hitting a transformer, or in terms of the physics of interrupted current? Either works depending on the circumstances.
- The idea is to carry the notion of “explanation” throughout the evaluation life cycle. In a sense this means considering “program theory” as an initial explanation that will evolve as the program continues.
- When we transfer the program to other settings, we continue the work of explanation. We begin with:
- The known effects of the program, and whatever we have gleaned about the interaction between the program and its context.
- We apply that knowledge to the new setting.
- We will never get it exactly right because any new program implementation cannot be exactly the same from setting to setting. And, because we are dealing with complexity, it is always possible that something about the new context will elicit unexpected behaviors.
- But it’s a good start, it and provides a solid framework for doing evaluation that will help us explain the scaled up situation.
- There is nothing unfamiliar about what I just said about program theory, but I hope you will see how program theory (aka explanation) fits into a complex system view of scale-up and replication.
- The key idea is what I discussed above.
- While complex systems can sometimes be unstable and unpredictable,
- they can also be very stable and predictable. (Although as I said, sometimes not in the usual ways we think about stability and predictability.)
- What is this predictability I am talking about?
- In some systems we can in fact identify a small number of factors that can reliably drive the whole system in a (reasonably) predictable direction. (E.g. setting rules or environmental conditions in an agent-based context.) So the whole enterprise of looking for factors that can explain scale-up makes a lot of sense.
- Complex systems can exhibit chaotic attractors. In a chaotic attractor you can predict absolutely where something will not be. But within the space of where it can be, it is impossible to know from one instant to the next where to find it. I’m not saying that scale-up situations are formally chaotic attractors, but the key insight holds. With respect to replication, programs may act as if they are in a chaotic attraction space.
- For both of these kinds of predictability, we do not have to understand (or even identify) all the interactions among elements. No matter what path something moves through the system, or what elements are or are not present, it is entirely possible that:
- One, or a small number of outcomes will manifest themselves, or that
- No matter what the convoluted path the program takes, the outcome on the other side can be well known.
- I started with an admonition to think in terms of explanation rather than prediction, but as you can see, I have been sliding into the “prediction” domain. Enough replication in a variety of settings, enough consistency in outcomes, and it is possible to have confidence in outcomes. But lest we get to smug…
- We are still working in a complex system, and all those elements (both knowable and unknowable), and all those feedback loops (with different latencies) and interactions, and all that dependency on initial conditions, and all the phase shift behavior that can happen, are bound to produce some unexpected consequences. (Book plug. Evaluation in the Face of Uncertainty: Anticipating Surprise and Responding to the Inevitable.) That’s why some ongoing M&E is so important. Unpleasant surprises need to be dealt with, and pleasant surprises need to be nurtured and understood.
- So we do not have to understand all the details of the system we are working in. Good thing, because it is impossible. But we do have to appreciate that no matter how predictable some elements of a complex system are, it is entirely possible that unexpected outcomes will manifest. And not just any unexpected outcomes, but ones that we may care about.
- This brings us back to the notion of evaluation as supporting explanation. As scale-up proceeds, we gain more and more experience as to:
- How to make things work in different settings.
- When (and under what conditions) we can make predictions.
- Whether we can be comfortable sliding from explanation into prediction, and
- How to keep an eye out for unexpected consequences that may have policy implications.
- It may be quaint to say it, but what’s needed is a shift from technocratic understanding to understanding through wisdom, as that wisdom is informed by technocratic activity.

I got an email from your blog asking for comments (not sure if that was bot or human generated). I don’t see anything to object in the discussion points and there is value in the points made. You also got a book sale from it :-). However there are some missing elements: granularity of the programmes being handled, nature of the evidence presented, gradient (differences) in the evaluation perspectives, separating objectives (complicated) from vector (complex) and a few others. Judgement for example, by who in what context?
>>The answer is that sometimes complex systems can be very stable and very predictable,
Jonny, I find your argument for this unpersuasive. That said…
The approach we’re using for scaling is “options by context.” This means that as the innovation is developed, complexity is anticipated and options by context is the approach to scaling from the beginning, even as the innovation is initially developed and evaluated. McKnight Foundation is using this approach with their international ag development initiative. MQP
Hi, Jonny:
I’ve had some time to review your blog post/AEA presentation. I admire your understanding of systems and evaluation. If I understand your thesis correctly, you are arguing that evaluation is useful in scaling up complex programs if we understand evaluation as providing program theory as an “explanation” that evolves as the program is scaled up. If that is your thesis, I recommend stating the need (or gap in understanding) your thesis fulfills much more clearly. Like, spend 30% of your time on it, because most people will not be ready for the nuance of evaluation as explanation so you need to prepare us. Currently you start with this, “This presentation will provide a theoretical framework that will show how those experiences make sense in terms of the behavior of complex systems.” To me, this sounds like you are going to explain how success is possible from scaling up a program. But I think you are more talking about how we should evaluate scaled up programs. (If not, I got your thesis wrong). In addition to a clear statement of purpose, it would be helpful to provide a contrast of what happens (or doesn’t) when we don’t use evaluation as explanation when scaling up; what is the alternative we must eschew to choose your way of thinking? Then, mirror that 20% at the conclusion—“Now if we use my idea, we can do this! And we could never do that before.”
While I saw the truth of your mini-thesis that sometimes complex programs are predictable, I didn’t quite make the connection to your thesis. Why does it matter for evaluation as explanation that sometimes complex programs are predictable? Is it that evaluation as explanation is only possible when complex systems are stable/predictable? If so, what do we do when they are not? Or is it that we can only scale up programs that are stable/predictable? The key turning point here seems to be “On the other hand, all the complex system behaviors I described seem to make the situation hopeless. If all that stuff is going on, how can we ever predict what will happen?” This needs to be a little more closely connected to scaling up or explanation. Maybe another sentence or two, which may come naturally out of clearly stating the problem in the first 20% of your talk.
Hope that’s helpful!
____________________
Bethany Laursen, M.S.