Table of Contents
Complexity is About Stability and Predictability
Example 1: Attractors
Example 2: Strange Attractors
Example 3: Fractals
Example 4: Phase Transitions
Example 5: Logistic Maps
Example 6: Power Laws
Example 7: Cross Linkages
Example 8: Emergence
What Does All This Mean for Evaluators?
Example 1: Attractors
Example 2: Strange Attractors
Example 3: Power Laws
Example 4: Timeframes, Attractors, and Power Laws
Example 5: Emergence
Example 6: Fractals
Example 7: Phase Shifts
Complexity is About Stability and Predictability

I have been thinking about how complexity is discussed in evaluation circles. A common theme seems to be that because programs are complex we can’t generalize evaluation findings over space and time because of the inherent uncertainties that reside in complex systems. (Sensitive dependence on initial conditions, evolving environments, etc.) The more I think about the emphasis on instability and unpredictability, the less I like it. See figure 1. Ban the butterfly!
Of course complex systems often behave in unexpected ways. But complexity is every bit as much about predictability and stability as it is about unpredictability and instability.
What complexity does is provide a different way to think about stability and predictability versus instability and unpredictability. The rest of this section presents examples of concepts that dwell within complexity science that exhibit high degrees of stability and predictability. In Section 2 I’ll take some of these and show how they can be applied in evaluation.
Example 1: Attractors
Wikipedia defines an “attractor” as follows:
“In dynamical systems, an attractor is a set of physical properties toward which a system tends to evolve, regardless of the starting conditions of the system. Property values that get close enough to the attractor values remain close even if slightly disturbed.”
Attractors have different shapes, some of which are “deep” in the sense that a system moving around in them cannot get out very easily, and some are “shallow” in the sense that a little bit of movement at the boundary can bounce them out. (The shapes can get complicated, but “deep” and “shallow” work for present purposes.)
It’s easy enough to think of an attractor in physical systems, e.g. the arc of a pendulum, a valley in a landscape, or the orbit of a planet. In the first case the pendulum will always move in a defined arc in a defined plane, and given the nature of dissipative systems, will come to rest at a well-defined point. A boulder will roll to the deepest part of the valley. The orbit of a planet is a bit more complicated, but the orbit is well defined and its position can always be identified at any point in time. Mathematical equations can also show attractor behavior. For example see Figure 6 (Example 5: Logistic Map). The top graph shows an attractor at 6.6. The middle shows an attractor that reliably jumps between 4.5 to 8.4.
What I like about the notion of an “attractor” is that it provides a framework for thinking about system change in terms of shape and stability, and in a way that allows comparisons across systems. There are other ways to think about the difficulty of change, e.g. “institutional inertia”, or “resistance to change”. There is nothing wrong with looking at change in these ways. I do it all the time myself to good advantage. And certainly, it’s possible to compare systems in terms of how resistant they are to change. But I find the notion of an attractor useful because it gives me a common, multi-attribute, framework to think about change.
In my business most of the systems I work with are so deep in their attractors that they have no idea there is any other place to be. It is their stability that drives me to distraction, not their instability. I have beaten many systems on the head for years and I can’t get them to change.
Example 2: Strange Attractors
There are many explanations of strange attractors to be found. The one that is most useful for me is:
“When a bounded chaotic system does have some kind of long term pattern, but which is not a simple periodic oscillation or orbit we say that it has a Strange Attractor. If we plot the system’s behaviour in a graph over an extended period we may discover patterns that are not obvious in the short term. In addition, even if we start with different initial conditions for the system, we will usually find the same pattern emerging. The area for which this holds true is called the basin of attraction for the attractor.
This is a fancy way of saying that there is chaotic behavior within some bounded space . (Of course “space” does not have to be physical or only two dimensional, but physical two dimensional cases are easy to visualize.) That means you can’t ever say where the position of a point will be based on knowledge of its immediate prior position, but you can know the shape of the space in which the point will exist. Wikipedia has some nice graphics and demos to illustrate chaotic behavior in a bounded space. One good one is the Lorenz attractor, see the butterfly (Figure 2). Another nice example is the movement of the double compound pendulum (Figure 3). Ignore the depiction of chaos in Greek mythology Figure 4 That’s another kind of strange attractor.
 |
 |
 |
Example 3: Fractals
Fractals show the same shape at different scales. The shape of a coastline is a classic example. Look at it from 1,000 feet up or a few inches away, and the shapes and curves will look about the same. If you just saw a few versions of the shape with no other cues, you would not be able to tell how far away you were.
“A fractal is a rough or fragmented geometric shape that can be subdivided in parts, each of which is (at least approximately) a reduced-size copy of the whole. Fractals are generally self-similar and independent of scale.”

Wikipedia has a nice picture of the fractal shape of ice crystals. (Figure 5.0) Fractals play an important role in complexity, and they are exceedingly predictable. In fact, their repetitious predictability is what makes them so interesting.
Example 4: Phase Transitions
A phase transition (also known as a state change) is a situation in which a system suddenly changes to a new condition.
Phase transition is the transformation of a thermodynamic system from one phase or state of matter to another. A phase of a thermodynamic system and the states of matter have uniform physical properties. During a phase transition of a given medium certain properties of the medium change, often discontinuously, as a result of some external condition, such as temperature, pressure, and others. For example, a liquid may become gas upon heating to the boiling point, resulting in an abrupt change in volume. The measurement of the external conditions at which the transformation occurs is termed the phase transition.

When these kinds of changes occur it is possible to predict exactly when they will happen. Think about water to ice or water to steam. Specify the temperature and pressure, and you know exactly what is going to happen. State changes do not seem as if they would be relevant in evaluation, but they are. Networks are a great example. Imagine a scatter of buttons lying on the floor. Pick two at random and tie a thread between them. Pick another two at random and tie a thread between them. For a while each additional thread will only connect buttons that are unconnected to any others. Eventually each additional thread will attach to a button that is already connected to other buttons. In the beginning these additional connections will only affect a small group of buttons. But eventually, and suddenly, adding threads will tie the entire group together. See Figure 6. That’s a phase shift. It’s not hard to imagine analogous situations that we deal with, e.g. multiple efforts to improve community wellbeing, or multiple efforts to build civil society in a developing democracy.
Example 5: Logistic Maps
A logistic map is:
a polynomial mapping (equivalently, recurrence relation) of degree 2, often cited as an archetypal example of how complex, chaotic behaviour can arise from very simple non-linear dynamical equations.
A simple example is the equation: Xn+1 = rXn (1-Xn) That’s not a very complicated equation. It is often used to look at the carrying capacity of a species in an environment. How many bunnies will be in the forest next year? The answer is:
- The number of bunnies last year, +
- a growth factor attributable to those prolific bunnies applied to last year’s population, x
- a factor that suppresses the bunny population as the bunnies begin to fill up the forest.

This seems straightforward enough, but surprises lurk. Tweak that “r” parameter and you begin to get chaotic fluctuations in the bunny population from year to year. (Try it for yourself.) See the pictures in Figure 7. (The equation that generated these adjusts the formula so that population is a percentage of the “annihilation value” at which all the bunnies disappear.)
r= 2.9 generational fluctuations converge on 6.6
- r = 3.4 generational fluctuations alternate between 4.5 and 8.4.
- r = 4.0 chaotic behavior is manifest, there is never a pattern across generations.
The value of “r” tells us exactly what the pattern will be each year, and exactly when the year to year change converts from predictable to unpredictable.
Example 6: Power Laws
A power law in statistics is:
a functional relationship between two quantities, where one quantity varies as a power of another. For instance, the number of cities having a certain population size is found to vary as a power of the size of the population.
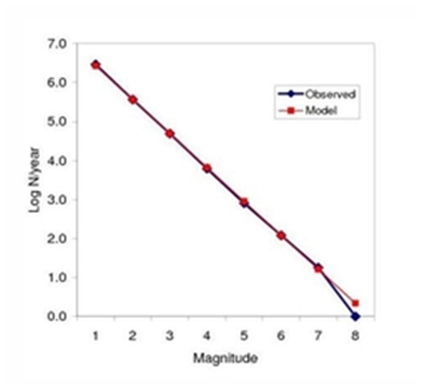
Wikipedia also has a nice graphic to illustrate this distribution. (See the yellow graph Figure 8.) We are awash in phenomena that are power law distributed, e.g. size of earthquakes, intensity of wars, number of acres burned by forest fires, magnitude of stock market crashes, number of criminal acts committed by a person, size of power outages, and a great deal more. What makes power law distributions really interesting is that if we do a log transform we end up with a straight line that shows the relationship between the number of cases and their size. We don’t know the size of the next power outage occur, and we don’t know when the next power outage will occur. But we do know the likelihood that when it does occur, it will be of some particular magnitude. Similarly with earthquakes. See Figure 9. Depending on what one wants to do with the data, that is quite a high level of predictability.
 |
 |
Example 7: Cross Linkages
The strength and profusion of cross linkages in a system can yield unpredictable change. For instance many cross linkages take the form of feedback loops, and we all know what kind of unpredictable behavior can come from multiple feedback processes that intersect and overlap. On the other hand, a profusion of supporting linkages can keep a system very stable for a long time in the face of external shock. Those systems may be brittle in the sense that when they do begin to break, the break can quickly ripple through the system. But for long periods of time the internal linkages do keep a system stable and predictable. And in fact this happens a lot, which is one of the reasons people in our business have so much trouble getting organizations to change. What about systems with many subsystems, each of which might be tightly linked, but which have weak links among them? A system like that may not be efficient, but it may well be highly adaptable to environmental change, and thus be able to maintain its integrity over a long period of time. emergence_explanation
Example 8: Emergence
In philosophy, systems theory, science, and art, emergence is the way complex systems and patterns arise out of a multiplicity of relatively simple interactions.

Look at the stupid bees in figure 10. Drop them into an inviting environment and they will go to work making an elaborate hive. That’s emergence. The shape and construction of the hive is exceedingly predictable. Drop the agents into the right conditions, give them the right rules about perceiving their environment and being able to take action, and you know you will get an elaborate pattern at a higher level of aggregation that cannot be explained in terms of the behavior of any of the individual agents. It is all very predictable.
What Does All This Mean for Evaluators?
I’m not trying to argue that that complexity has nothing to do with instability and unpredictability. Of course it does. I only want to make the point that complexity is also about stability and predictability. And in fact, you can’t understand one without the other. I also don’t mean to imply that all the examples I just gave can be used in evaluation. I only cited them to make my point. But I can see how some of the examples provide ways of thinking about the world that are relevant in evaluation. Here a few examples.
Example 1: Attractors
Here are two examples of very different organizations. I’ll describe their developmental paths in terms of attractors, one of which moves in a single direction, and one of which swings back and forth like a pendulum. The pattern is predictable, and knowing the pattern helps me understand how those organizations behave over time, and to appreciate the implications of their different trajectories.
National Security Agency
Think about the NSA (a topic much in the news as I am writing this.) The NSA exists in an environment with a few conditions: 1- It has a mission. 2- Fulfilling that mission is assisted by collecting as much information as possible. 3- It exists in a legal framework that allows it to collect information. 4- Because it’s activities are hidden, it can push the boundaries of the legal framework. 5- It has access to technology that can collect and process vast amounts of information. 6- It is able to recruit supremely talented people in cryptology and data mining. I’d say these characteristics put the NSA in an attractor that moves ever more in the direction of collecting more and more information. It’s not clear what the end point of the movement is, or even if there is one. But the shape of the attractor is pretty well defined. Of course NSA’s environment has changed recently, but by how much, and whether the changes will really change the shape of the attractor, is unknown. Or put another way, we do not know how stable and deep the attractor is, or how strong the environmental shocks to the system will be.Federal Regulatory Agencies
If you look at regulatory agencies over a long period of time there seems to be a pendulum-like effect in the way they deal with the industries for which they are responsible. One approach is to adopt a highly cooperative position. With the cooperative approach the agency works with industry to identify and resolve safety problems. There is a focus on specifying requirements, but giving industry a great deal of latitude in how it meets their obligations. Fines and punishment are used as a last resort. A second approach is to be highly rule-bound, inspection-bound, and punitive. There are lots of advantages and disadvantages to each approach. Regulatory agencies can be seen to move back and forth along a continuum with different degrees of emphasis on each approach. That’s an attractor. It is a description of system behavior that can be observed and defined.
What if I were to evaluate a program designed to facilitate inspection and punitive behavior in a regulatory agency? Because the notion of attractors is part of my intellectual toolkit, I’d start by asking myself: Is there an attractor that governs how the agency is operating? Because I’d understand what the attractor was, I’d build a monitoring function into the evaluation to determine which way the agency was moving in its attractor during the life cycle of the program. If the momentum were moving toward a cooperative stance, I’d set lower expectations for the effectiveness of the program. The lower expectation would drive a methodology aimed at detecting smaller changes, and also, a larger number of finer-grained intermediate outcomes. I’d query the stakeholders more forcefully as to why they thought the program could succeed. I’d probably do a more thorough job of assessing organizational support for the innovation. I can’t say that thinking in terms of attractors would be the only reason I’d construct the evaluation this way. I’m pretty good at my job, and I’d probably end up doing the same things even if I took the traditional approach. What I do believe, though, is that by starting with an appreciation of the agency’s attractor behavior, I’d have a useful framework for making a large number of related decisions about the evaluation design. I’d also have a solid foundation for interpreting my data.
Example 2: Strange Attractors
I see strange attractors as a particularly useful notion in the evaluation business because they involve “bounded chaos”, i.e. unpredictability within a “space” whose boundaries can be identified. That sounds like a pretty good description of a lot of evaluation – we know many of the outcomes we can expect to see across settings, but: 1) We don’t know which ones will show up in any given case. 2) We don’t know the interactions among the outcomes that explain why a particular set of outcomes shows up.
To illustrate I cooked up a hypothetical example that a friend in the field of educational evaluation assures me is not too far off the wall. Imagine an innovative program to help teachers do better classroom management. Let’s assume the program works, i.e. teachers do in fact get better at managing their classrooms. Let’s also assume the effect is fairly robust, i.e. it helps most teachers, in a wide variety of teaching environments, to do better classroom management. What outcomes that might ensue? 1) More teacher job satisfaction. 2) Greater student satisfaction with being in class. 3) Higher scores on various tests. 4) More homework completion. 5) Fewer absences. 6) Less tension between teachers and principals. 7) Better interaction between teachers and parents. 8) More on-task behavior by students during class. 9) Fewer disruptive students. This is not a complete set, and it’s probably not a correct set. Some are more likely than others. But with enough empirical research across classroom settings, a pretty complete list could be developed.
What cannot be developed, though, is knowledge of which effects will show up where, or which particular effects interact with other to bring still others about. For instance, in one case student satisfaction and more homework completion may combine to improve test scores. In another, parent involvement and on-task behavior may have been the reasons for higher test scores. In another case student satisfaction and less classroom disruption might combine to improve teacher satisfaction, which would then lead to higher test scores. And so on and so forth. In any given classroom there will be a Gordian know of relationships among outcomes that can never be untangled. What we do know however, is the set of outcomes that can be expected. That’s bounded chaos. That’s a strange attractor. That’s a pretty decent level of predictability with all manner of implications for methodology, policy making, and estimating educational impact.
Example 3: Power Laws
If I were evaluating a new math curriculum I would be pretty comfortable thinking in traditional statistical terms. Whatever effect the new curriculum will have, there will be a mean and a standard deviation. The distribution might not be normal or even precisely symmetrical, but I bet it would be close. Contrast this case with an evaluation of a new business start-up incubator. Most of the new businesses will fail. A few will have reasonable amounts of growth, and a very few would really take off. That’s a power law and if you did a log transform you would get a nice straight line. (Actually it’s not so easy to know if the graphs accurately represent a power law, but it’s close enough for this conversation.)
What does the power law distribution imply for evaluation? It implies that although you could do the arithmetic to calculate a mean effect, that knowledge would not be very useful. What is useful is to know the proportion of large, medium, and small changes. Success would be an incubator that shifted the distribution a bit to the high side, but knowing that most cases will still be failures, or at least, only small successes. Think of the policy implications. In the math curriculum example the success claim would be: “We shifted the average achievement score for all the kids.” In the business start up example, the claim would be: How clever we were to have funded a portfolio of start-ups in which a few more were successful than if we had not established the incubator, even though the vast majority of the projects we funded were still failures”. That’s a different way of defining success.
In addition to the policy implications there are also methodological implications. In the math curriculum example, qualitative case studies would be nice but not essential. But I don’t see any way of doing a good job of evaluating the incubator example without doing in-depth case studies. I’d do as many of the large and medium success cases as I could, and then draw a random sample of the many, many cases that had minimal success, or failed. (For a longer discourse on this subject go to: Power Law Versus Symmetrical Distributions — Implications for Policy Recommendations.)
Example 4: Timeframes, Attractors, and Power Laws
The kinds of systems evaluators tend to deal with may be stable over a period of months but not years, or years but not decades. Within the time spans of stability, it can be helpful to think about the system as moving about in its attractor, and the likelihood of the system being kicked out of its attractor. How does this approach differ from the traditional way of setting up an evaluation?
Traditional approach
The way I usually design an evaluation is to posit a theory of change and then to evaluate whether an innovation based on that theory of change was powerful enough to change the status quo. For instance, suppose I was evaluating whether a best practice adopted. I would conjure up Rogers’s theory of innovation adoption, assess the characteristics of the innovation, the adopters, and the setting, and figure out what is what. Suppose I was evaluating whether an NGO’s development program helped a country along the road to democracy? I’d invoke the theory of the relationship between civil society and democracy, and do the evaluation. Doing evaluation this way is a good idea, especially when the program theory is backed by substantial empirical research.Complexity approach
Here is another way to go about it. Not better, but different. Different in the theory of change, different in the methodology required, and different in the knowledge it produces. In this approach I would take the view that no matter how powerful, and how well validated a specific theory of change might be, it would still be possible to get the same result via numerous other paths. Another way to state this view is to say that we might not know precisely what will happen, but we know the probability that something will happen to move the system outside of its attractor. We want to know the answer to three questions. 1) What is the probability of something occurring within a particular period of time that is consequential enough to change the effectiveness of the program being evaluated? 2) How often do perturbations of that size occur? 3) Is the program being evaluated powerful enough to bring about the needed degree of change? These are empirical questions. What is the methodology to answer these questions? Plot the system over as extended a period of time as possible. Count the number and magnitude of perturbations to the system. Assess the consequences of those perturbations. (I’d bet you would see a power law type distribution, but then again, maybe not.) Design and execute an evaluation that is capable of determining whether the program in question reached that threshold, how close it came, and what would be needed to get it over that critical value.
I don’t want to minimize the difficulty of applying the complexity approach in evaluation. Determining the occurrences, magnitudes and consequences of organizational, societal, and policy changes are a lot harder to determine than occurrences and magnitudes of earthquakes, stock market crashes, or hurricanes. It’s all too easy to toss out the notion of a “program being powerful enough to bring about the needed degree of change”. Getting data to answer that question is not so easy. But difficult as it may be, a adding the complexity perspective to an evaluation would produce a lot of useful information. First, it would provide a reality check on whether substantial change could be expected. Second, it would provide a sense on how close the program came to being capable of inducing noteworthy change. (Think of the inflection point in example 7.) Third, it would help us understand whether it’s even possible that a single program could bring about major change. After all, suppose I’m wrong about the power law and there is no inflection point? Suppose what we really have is linearly incremental improvement moving up a gentle slope? That would make it a lot easier to attribute value to the program being evaluated. As I said, this all this information is not better than applying a well-tested program theory.
I need to emphasize that I am by no means advocating abandoning the traditional approach. I would never give up the traditional way of doing things, and I can’t imagine anyone else doing so either. I even think that using the traditional approach is a requirement for doing right by our customers and stakeholders. What I do believe, however, is that the complexity approach relies strongly on the notions of predictability and stability. Within a reasonably determinable timeframe, the concepts of attractors and power laws can be used to determine the stability of a system that a program is trying to change, the developmental trajectory of that system, and the likelihood that a particular program can bring about a policy-relevant change.
Example 5: Emergence
For me emergence is most useful in the realm of program theory because it provides an alternative view of how a social system might work. The best example I can point to is the NetLogo simulation of red and green turtles in a pond. (Obviously not much of a stretch to think about segregated neighborhoods.) To quote from the description of this simulation: (Follow the hyperlink. You will be able to run this simulation for yourself in your browser.)
This project models the behavior of two types of turtles in a mythical pond. The red turtles and green turtles get along with one another. But each turtle wants to make sure that it lives near some of “its own.” That is, each red turtle wants to live near at least some red turtles, and each green turtle wants to live near at least some green turtles. The simulation shows how these individual preferences ripple through the pond, leading to large-scale patterns.
Graduate from turtles to people and pretend that we are evaluating a program designed to keep neighborhoods from segregating. We could apply two different program theories to the evaluation. One would explain segregating neighborhoods in terms of social policy, economics, bank lending procedures, and so on. The other would explain segregation as an emergent property of individual decisions about not having too high a percentage of people near you who are not of your own kind. The different program theories would drive decisions about sampling, measurement, comparison groups, interview protocols, data interpretation, and policy recommendations. I don’t know how God runs the world and I don’t know which program theory is more correct or more useful. But I do know that the emergence-based explanation is compelling enough to be taken seriously. Of course, this is a contrived example because fair housing laws more or less trump all. But contrived or not, it’s a good example of how thinking about emergence can change one’s view of program theory, and the decisions that flow from applying one or another theory.
A colleague and I have been testing ways in which agent-based models can be used in evaluation. If you want to know more:
- See how the model runs.
- Hear me talk about how we developed the model and why.
- Read our paper. Emergent Consequences: Unexpected Behaviors in a Simple Model to Support Innovation Adoption, and Planning, and Evaluation.
- Get in touch with me.I’ll set up a Webex session.
Example 6: Fractals:
Fractals look the same at different levels of magnification. An analogous kind of similarity can take place in social systems. These are not fractals in the formal, physical, sense, e.g. they don’t have fractal dimensions that describe how detail changes with scale. But the idea of things being the same at different scales is a useful way to think about the systems we work with. If nothing else, it’s a useful counterpoint to believing that emergence and change are ubiquitous in all the programs we evaluate.
An example that works for me is coalition behavior. In a coalition there are various groups which join forces in pursuit of their own self-interest. Coalitions are ubiquitous in organizations. In fact, observation of coalition behavior is one of the ways in which organizational behavior is studied. How might one use this idea in an evaluation? Think about a multi-level nested system, say specialty sections within a department in a university, departments within schools, schools within the entire university, and individual universities within a state system of universities. I’d venture to say that at each level, (i.e. at each subsystem), there are coalitions operating. The objectives of each coalition may be different, the way each coalition goes about pursuing its interest may be different, the stability of the coalitions may be different, but coalitions there will be.
Suppose a change were introduced into the system? Maybe there is a policy change related to acceptance policies and the makeup of the student body. Maybe there is an effort to facilitate more inter-disciplinary research across departments. Maybe the budget is cut. How might the change be evaluated? One way to do it would be to assume that the coalitions within each level see their own opportunities and challenges with respect to the self-interest that formed the coalition in the first place. If I wanted to understand how the university was responding to the change, I might look at coalition behavior at each level. I would do so with confidence that things like coalitions existed at each level, and that the methodologies of coalition assessment were the same. This is a form of predictability. On the basis of what is known about organizational behavior I would be confident that I could look into many nooks and crannies of the university and find similar entities, behaving according to similar rules, but working toward different purposes. Would this investigation also rely on stability? Most emphatically not because it is entirely likely that old coalitions may break and that new ones might form. That’s evaluation data. Of course this example is over-simplified because it ignores possibilities such as coalitions across organizational boundaries, but I hope it makes the point. Coalitions are not fractals in the technical sense of the term, but they are entities that repeat in form at different scales, and that can be reliably expected to be present at different scales. That affords a level of predictability that can be very useful in understanding how a change may affect an organization.
Example 7: Phase Shifts
Figure 6 and it surrounding text show how phase shift behavior can apply to the kind of networks that evaluators may deal with, e.g. multiple independent efforts to improve the wellbeing of a community, or multiple independent efforts to improve civil society in developing countries. To pursue the community wellbeing case, imagine a community in which there are five projects, each designed to achieve a specific objective that can be said to contribute to the greater goal of “community wellbeing”: 1) insert a food oasis into an urban food district, 2) a voter registration drive, 3) tutoring project for at-risk kids, 4) improved street lighting project, and 5) a parenting education program. The critical evaluation questions for each of these five programs are obvious. Is healthier food available to community residents? Were more voters registered? Did at-risk kids get effective tutoring? Was street lighting improved? Did parents learn how to take care of their kids? But if we took a systems view of the evaluation, we might think each program in terms of its contribution to network development. This perspective opens up evaluation questions relating to network nodes (each program), and network edges (connections among programs).
Edges: What are the consequences of the number of edges in the network increasing? Maybe the same person taking parent education classes becomes more socially conscious, and thus become more likely to be influenced to register to vote. Maybe because the streets are perceived to be safer (better lighting), parents are more willing to let their kids attend tutoring sessions. Maybe the leadership of the various programs begins to overlap as each new program seeks talented leaders and staff.
Nodes: It is also possible that because of all the developing connections, new programs (nodes in the network) come into being. For example, perhaps conversations among each program’s leadership raises the awareness that a program not yet in the community needs to be there, say for instance, a something to provide company for shut-ins, or a community newsletter blog.
I have just described a network development scenario not unlike the button and thread case shown in Figure 6. Thinking in these terms raises some important questions about methodology and program theory.
Methodological questions
Is this really a scenario that can be understood in terms of network behavior? I think I have made a reasonable case that it can, but whether network dynamics are really in play is an empirical question. If network behavior is operating, there are expectations for the pattern of change that would be observed. We would expect gradual change in overall measures of community well being, and then a very sudden change (a phase shift) to a much higher level. If we believed this, it would be particularly important to use a time series design because such designs are so well suited to identifying when a phase shift occurs, and the condition of the network was in when the shift occurred.
I assumed that there is such a thing as “community well being”, that it can be measured, and that the immediate outcomes of each program reflect some aspect of that global outcome. Those are whopping big assumptions that would need to be tested. I noted that new programs may develop that would count as new nodes in the network. But what new program should count as a node? Anything that might have some chance of improving the social good? Or do we need to be more discriminating? What counts as a connection in the network, and how should a connection’s strength be measured?
Program theory
If we care about community well being, does it make sense to evaluate any single program unless we could also look at the others, and also include a global measure? Put another way, is it adequate to have a collection of individual program theories, or do we need to tie them together with a theory about network formation? If we were content with only measuring immediate outcomes (I would be), is it legitimate to construct a logic model that shows a direct relationship between proximate and distal outcomes? If the goal is community wellbeing, does it matter which programs we implement, or do we operate on a program theory that only cares about the numbers of effective programs, not the specifics of their outcomes? To make the case that we don’t care, think of the button example. At the start of each experiment each all potential node is equal to all the others. (“Potential” because there are no connecting edges yet.) It is only the random development of connections that makes some nodes more important than others. While on any run of the experiment some nodes take on particular importance, in the long run none of that matters. All that matter is that when a certain degree of connectivity occurs, the phase shift takes place. If behavior like this held for the community wellbeing example, it would not matter what programs were funded. The only thing that would matter is the number of programs and the capacity of each to form connections with the others. So do we want to make funding decisions based on specific needs that could be addressed by each program? Or do we what to decide based on the likelihood that a program will be able to connect with other programs? It’s a radical thought, but maybe we do. I’m not advocating that we do. I only want to make the point that phase shifts in networks is a predictable aspect of the system’s behavior, and that knowing that such behavior will manifest itself can lead to consequential decisions about evaluation design.
Acknowledgements
Whatever you think of this post, it would have been a lot worse but for critique from a lot of people. Thanks go to: Tarek Azzam, MaryAnn Durland, Kim Fredericks, John Gargani, Mary McEathron, Curtis Mearns, Janice Noga, Michael Spector, Allison Titcomb, Mat Walton, and Jeff Wasbes.

{kind=link}
{kind=link}
Great post. The best I have read on evaluation and complexity in a while with good examples and even better sidenotes (“I have beaten many systems on the head for years”). I agree that among many folks working in complex spaces/programs/environments there has been a denial or rejection not only of any predictive ability but also accountability to any predictable outcomes.
Thanks so much for sharing this brilliant info!
I’m excited to see more posts!