I have been involved in evaluating distracted driving programs for transportation workers. While working on the evaluations I developed an interesting way to understand how programs are acting and what they are doing. The method is based on a few principles, one set focusing on the nature of timelines and schedules, and the other on data collection.
Timelines and schedules
Timelines and schedules matter. These documents are constructed to meet a few objectives. They have to:
- Provide a reasonable plan whose tasks can be executed.
- Represent a reasonable correspondence between budget and work.
- Satisfy customers desires for when the work will be completed, and for how much.
In a sense there is a conflict between the first two objectives and the third, resulting in overly optimistic assessments of budgets and timelines. That’s the direction of the bias in our estimates.
- Schedules always slip. We blame Murphy, and take the problem for granted. We shrug, that’s the way it is. But in fact, “that’s the way it is” is there are some important system-based reasons. We have to take these reasons seriously.
- There is inevitable tension between technical and social/business purposes of schedules and plans.
- Even if our estimates for time and budget were unbiased, they would still have a degree of uncertainty. Those kinds of uncertainties have a nasty way of piling up and influencing each other.
- Murphy was not quite right. To say: “If something can go wrong it will” is tantamount to saying that everything will go wrong, and of course this is not true. What is true is that: Something will go wrong. Why? Because a schedule can be seen as a fixed system that is set within, and has linkages to, a continually changing complex environment. What this means is that no matter how smart we are, no matter how experienced we are, no matter how diverse our team, we cannot devise a project plan that will account for all contingencies.
My evaluation insight was that project delays can teach us something. That led to some questions:
- How can an evaluation extract useful knowledge from the inevitable bias and error that is contained in a project plan?
- What can be learned from discrepancies between when a plan said that something would happen, and when it really did happen?
- If we can’t use a plan to predict future events, can we use it to explain why the program behaved as it did?
Data collection
It’s sometimes hard for me to get my customers to believe what I’m about to say, but it’s still true. A little bit of data, collected regularly, is much better than trying to collect a lot of data at regular intervals, and it is surely better than collecting a lot of data at irregular intervals. Why?
- People have trouble with the idea of collecting only a little bit of data because once they agree to collect any data at all, their imaginations runs wild with the possibilities. They are seized with the fantasy that they will use all the data they can imagine. Worse, they think they will use that data because it matters. I’m OK with that if the data are generated passively, but too often getting data requires asking people to do some work. People need to take time when they are interviewed. Data administrators need to take time to extract data and transform it into usable form. And so on and so forth. These efforts almost never relate to people’s core work missions and thus, tend to not be done well. (Except of course for the evaluator, who is stuck getting people to do extra work.)
So why not ease the data collection burden by collecting a lot of data at infrequent intervals? Because by doing that, important evaluation information will be missed.
- It becomes difficult to identify transition points, i.e. when a program or outcome shifts in a significant way. And knowing when those transitions happened is important for understanding program behavior and outcome.
- Small, but important events may be missed, i.e., those occurrences that seem trivial when they happen, but which determine trajectories over time. If you wanted, you could think of this in terms of sensitive dependence on initial conditions. There are two reasons why frequent regular data collection is needed to detect these events. First, people may not remember them after some time has passed. After all, the events in question can seem so trivial that they were not noticed when they occurred. Second, not all small events affect the future. In fact, the vast majority do not, and without regular data collection, it’s impossible to determine which small events mattered. (In general I am adamantly opposed to the vogue in evaluation of attaching so much importance to sensitive dependence on initial conditions. Evaluators have to appreciate that complex systems can be very stable and predictable. Ban the butterfly!)
What to do? Carefully decide what information is needed. Strip the list to the bone. Collect it frequently. If some pattern emerges that seems important, do a deep dive to find out what is what.
Development and presentation
I’d like to say that the notions in this blog post resulted from rigorous thinking about the nature of schedules, psychological estimation bias, organizational behavior, and complex systems. But that would be a lie. What really happened is that a piece of the idea popped into my head for no apparent reason. It just seemed like a good idea at the time. Over the next few months, aided by time in the sauna, other pieces crept in. This was no coherent intellectual effort, that’s for sure. Afterward I looked back at what I did and decided that in some subconscious way, I must have applied the logic above about timelines and data collection. I’d like to think I’m right about this, but who knows?
What follows is an explanation of what I’m doing, written as if I were actually evaluating a program as described. I’m not. I am working on programs like this, but what follows is a mash up, along with some artificial examples thrown in to help me make some points. I’m a big believer in synthetic examples, i.e. examples that show verisimilitude to real cases, but which contain additional detail. I use these because I have found that very few real cases contain all the elements I need to explain whatever points I want to make.
The Program
The program is run by a committee of employees who are implementing an anti-distracted driving program for their workplace. There are nine people on the committee. There are also three other key players – the boss, a representative of the corporation, and a consultant who is providing training. That makes 12 people. I do a phone check with one of them each week, on a rotating basis. I’m also collecting a lot of other data, some internal to the program and some not.
- Internal data includes records of material passed out, numbers of training classes, and the like.
- External data comes from an environmental scan, e.g. – stories in the popular press, decisions by the company, decisions by relevant federal agencies.
The questions are pretty straight forward.
- What has gone on recently that has had an important impact on how the program is going?
- What is coming up in the near future that is going to have an important impact on how the program is going?
- Considering everything so far, how satisfied are you with how the program is progressing?
- Has there been any change is what you think success will “look like”?
- If you had to bet $5.00 on what people will think of the program at its end, how would you bet? (Everyone should ask a question like this. All kinds of juicy information crawls out).
I’m combining all the data to construct five timelines.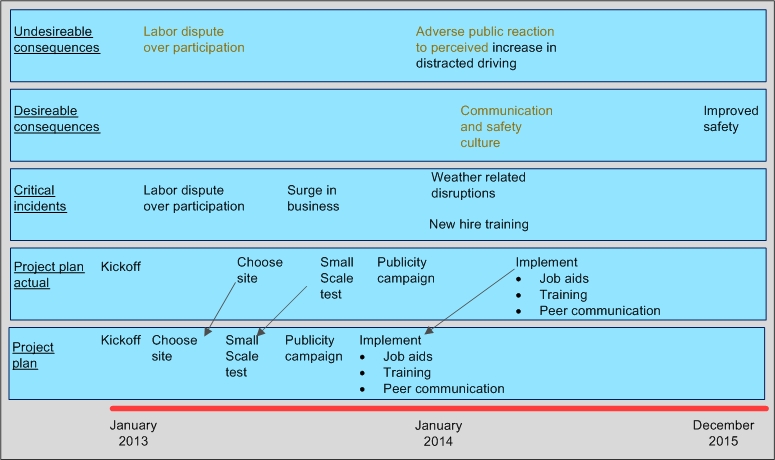 (Click on the image to get a high resolution view.)
(Click on the image to get a high resolution view.)
- A garden variety timeline that comes right out of the project plan.
- Actual times when planned events occur.
- Noteworthy events that occurred that were never part of the timeline
- Desirable consequences of the program, color coded for
- expected (black in the picture) and
- unexpected (orange in the picture)
- Undesirable consequences of the program
- expected (black in the picture) and
- unexpected (orange in the picture)
Using the Data to Understand the Program
As a first pass, I am using the streams to construct a rich description of the program that I would not have perceived by just looking at interview notes, survey data, and quantitative measures of the company’s functioning. One of the things I discovered over the years is that most (maybe even all) people involved in a program actually do not have a very good understanding of what has been going on. They are so busy doing the hard work or running the program to look much beyond their immediate boundaries. People learn a lot from seeing the overall picture.
Beyond the rich description, looking at the data this way forces me to consider relationships among the streams in a connected, systemic, way. Without the visual there are all kinds of issues I would never consider, or analyses I would not have done.
Of course not everything on the time line is connected, and a great deal of useful information is somewhere else in the data (I hope). Still, it is the visual relationships that forces me to pay attention. For instance, here are a few of the things the parallel stream would make me think about.
- At the beginning of the program everyone assumed that all relevant labor crafts would agree to participate. This was a reasonable, but incorrect assumption, and goes a long way to explaining why the start of the program was delayed. This event may end up having serious consequence for the success of the program because it shortens the time between full implementation and the end of the test period. (The end is a hard stop.)
- I also recorded the labor dispute as an undesirable unexpected consequence. I’m still thinking about this. It was “unexpected’, but by no means “unexpectable“. (It’s pretty close to the “foreseeable” category in my typology of evaluation uncertainty). So is it a critical incident, an unexpected consequence, or both? Ultimately I will make the decision based on how useful each choice will be explaining the program.
Once the site was chosen, small scale testing took place in about the same amount of time as was estimated in the original timeline. This, despite the fact that a surge in business (second critical incident) is something that would reasonably be expected to slow down implementation. Odd. This observation makes it worthwhile to take a deep dive look at how the small scale test was actually implemented, who did it, and why it could have been done on time. Knowing that might make for useful advice to anyone working in similar conditions.
- The longest time lag was between small scale testing and full scale implementation. The critical incidents provide a clue as to why this delay took place.
- A combination of weather and new hiring may have been the proximate reasons why full scale implementation was delayed for so long.
- I’d also look at whether the surge in business was still going on, because that might also be contributing to the delay.
A tangent on how I interpret critical incidents and consequences
I treat the critical incidents as only one possible hypothesis. They are not the only explanation, but they provide a good place to start, and frequently, they do provide the correct explanation. But It is entirely possible that other factors may be at play. For instance.
- There may be incidents that nobody thought of as “critical”, or even knew about, that were responsible. Maybe nobody attributed much importance to the fact that the steering committee missed a few meetings. Perhaps people did not know that the corporate representative was distracted by other pressing matters, and thus did not attend to some important behind the scenes decisions.
- Another plausible explanation is the “stuff happens” hypothesis. Here, an accumulation and interaction of small events combine to have large consequences for the course of events.
- In an ideal world my program monitoring system would detect all of these possibilities. But if I lived in an ideal world I would not have to do this evaluation in the first place. What I can do is to:
- Set up the regular check-in monitoring plan so as to include as many “close observers” of the scene as possible, and
- Set up the project budget to allow me to do some additional investigation.
- Note the unexpected desirable change in communication and safety culture. What’s that doing there, so early in the project’s life cycle, even before full scale implementation? (Let’s assume there are elements to the methodology that allow me to detect the change and to attribute it to the program.) “Project plan – actual” gives me a hint. The impact showed up at about when the publicity campaign kicked in. Could it be that the fact of the program’s existence is enough to improve communication, even before any tangible impacts showed up? This is a speculation worth a deep dive because it has consequences for understanding what might happen when programs like this are implemented.
- As for the adverse public reaction. Is it really “unexpected”? Well, I thought it would happen, but I could not convince people to add it to the logic model. So I put it in the “undesirable” stream and color coded it both orange and black. I do know that the public reaction showed up at about the time I thought it might, i.e. when the publicity campaign kicked in, and way before the program had any chance of showing that it was improving safety. (Maybe the planners should have put in a shorter term intermediate positive outcome, but they did not. Another object lesson.)
What This Approach is Not
I have no illusion that looking at the program this way is the be all and end all of an adequate evaluation design. For instance, look at what is missing.
- There is no methodology to determine causation – if safety is shown to improve, did the program have anything to do with it?
- I have no idea how the publicity campaign was received because there is no social marketing analysis.
- “Implementation” includes job aids, training, and peer to peer communication. If I can’t show that these were done well, I’ll have a hard time attributing causation if changes in safety are detected.
What I actually have been doing is embedding my five streams in an overall design that will address all these issues. What I have been finding is that:
- A great deal of useful knowledge is coming from the streams alone, and that
- The knowledge gained is very useful for understanding all the other aspects of the evaluation.
Value as Explanation
I began this blog post with a discussion of why timelines are unpredictable and that something is bound to come up that will perturb plans. I also made the point that whatever those somethings are, they are unpredictable, and hence, will be different from program implementation to program implementation. If that’s the case, what good is doing an evaluation that looks at critical incidents for particular slips between plan and reality? I have three answers to this question.
- In large measure evaluation is about explanation, not about prediction. Further, explanation is valuable for program planning even though the explanation is not generalizeable in the formal sense of the term.
- What I said about the uniqueness of unexpected events is not quite true. I do think that some unplanned events are predictable, especially if the level of detail is kicked up a bit. For instance take the labor dispute I mentioned. It may not have been possible to predict the precise nature of the reason that one union did not want to participate, but it might have been reasonable to expect that some such issue would delay the project’s implementation.
- I’m convinced (although I can’t prove it) that patterns of events may reappear over time. To continue the labor example, the program was delayed not just because one union did not want to participate, but also because the funder had strong reasons to want participation from multiple unions. I can easily imagine a dynamic like that playing out over multiple project implementations. In other words, the explanation gets stronger (and closer to predictability) as the evaluation is repeated for similar programs in similar contexts.
Level of Analysis, Fractals, and Power Laws
In the discussion above I ignored the matter of the level of detail at which the program plan should be pitched. After all, every task can be decomposed into many smaller tasks. “Big fleas have little fleas, / Upon their backs to bite ’em, / And little fleas have lesser fleas, / and so on, ad infinitum.”
What is the right level of detail? There is no right answer to this question, but there is plenty of experience and craft knowledge about how to answer it. As with any evaluation that works with systems, the evaluators and the stakeholders need to contemplate (and argue about) what is “in” and what is “out” in order to do a meaningful analysis. These arguments always work out (well, almost always).
A complication is that an evaluation may need to work at more than one level of detail, so a decision has to be made about a set of levels. That decision has to be based on what program theory says may be important, what experience says may be important, and resources available. (As an aside, I do not believe that any level of detail can be explained by combining knowledge from lower levels of detail. Each needs to be understood in it’s own right. My reasons for this belief would require another whole blog post.)
When it comes to levels of detail, here is something else that I’m sure is true but I can’t prove. The timing of the schedule slips is fractal. For instance, let’s say that for a year-long project, three delays occur. One represents 30% of the project length, one 20%, and one 10%. If instead of a year for the whole project, slips were recorded for a six-m0nth interim deliverable, the 30-20-10 percentages would show up. And so on as choices are made for higher and lower levels of detail.
Something else I’m sure is true (on faith, of course) is that the length of the delays are power law distributed.To explain, imagine a graph: X axis = number of delays. Y axis = length of delay. I’m sure that plot would show a power law.
What I’m not sure about is whether the shape of that power law would be different for different kinds of programs, or for similar programs that are embedded in different settings. Figuring that out would be a really cool exercise, but not for now.

2 thoughts on “Timelines, Critical Incidents and Systems: A Nice Way to Understand Programs”